Table of Contents
Using Selenium in data scraping is quite a common thing. It automates browsers and allows you to simulate real user activities to avoid getting blocked. It is especially helpful while scraping JavaScript dynamically generated sites like Google. Moreover, it helps to avoid any kind of crawling protection as it basically simulates real clients’ behavior.
In this article, you will see a step-by-step tutorial of developing a scraper that will be able to parse places from Google Maps without getting blocked even after 1000+ pages.
What We'll Need to Build The Crawler
- Python 3+.
- Chrome browser installed.
- Selenium 3.141.0+ (python package).
- Chrome Driver (for your OS).
- Parsel or any other library to extract data from HTML like Beautiful Soup.
Step by Step Tutorial to Build The Google Maps Extractor
Download and Save ChromeDriver
To use Selenium with Google Chrome you will need to link python code to the browser by using ChromeDriver.
Download the version of ChromeDriver that matches your browser version and OS type. Your Chrome browser version number can be found here: Chrom -> Menu icon (upper right corner) -> Help -> About Google Chrome.
Unarchive chromedriver file and save it somewhere on your system (path to it we will use later on). In this tutorial example, we store the file in the project folder.
Install Selenium And Parsel Packages
Install Selenium and Parsel packages by running the following commands. We will use Parsel later when we will parse content from HTML.
pip install selenium
pip install parsel # to extract data from HTML using XPath or CSS selectors
Initialize And Start Webdriver
Before initializing Webdriver make sure you did the previous steps and you have the path to your chromedriver file. Initialize the driver by the following code. You should see the new Chrome window open.
from selenium import webdriver
chromedrive_path = './chromedriver' # use the path to the driver you downloaded from previous steps
driver = webdriver.Chrome(chromedrive_path)
On mac you might see the following: “chromedriver cannot be opened because the developer cannot be verified”. To overcome this control-click the chromedriver in Finder, choose Open from the menu and then click Open in the dialog that appears. You should see “ChromeDriver was started successfully” in the opened terminal windows. Close it and after this, you will be able to start ChromeDriver from your code.
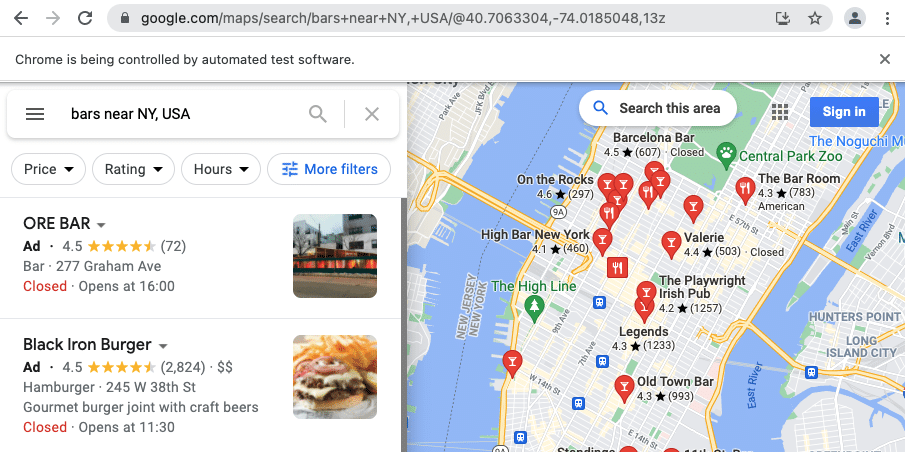
Download Google Maps Page
Once you start the driver you are ready to open some pages. To open any page, use the “get” command.
url = 'https://www.google.com/maps/search/bars+near+NY,+USA/@40.7443439,-74.0197995,13z'
driver.get(url)
Parse Maps Search Content
Once your page is opened you will see the page in your browser window that is controlled by your python code. You can run the following code to get the HTML page content from ChromeDriver.
page_content = driver.page_source
To comfortably see the HTML content, open the developer console in Chrome by opening the Chrome Menu in the upper-right-hand corner of the browser window and selecting More Tools > Developer Tools. Now you should be able to see elements of your page.
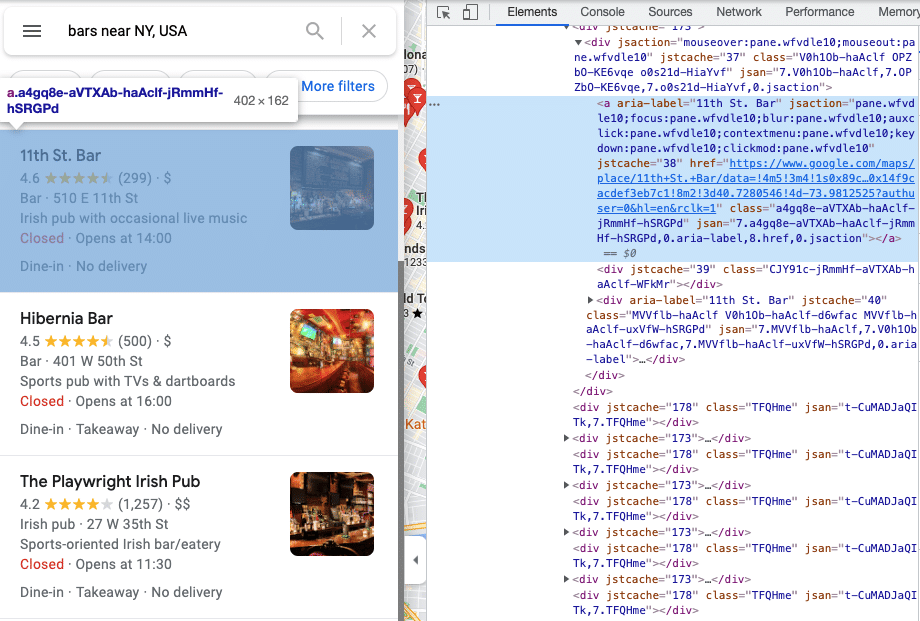
You can parse the content from the HTML page by using your favorite parsing tools. We’ll use Parsel in this tutorial.
from parsel import Selector
response = Selector(page_content)
Iterate over listings and get each place’s data.
results = []
for el in response.xpath('//div[contains(@aria-label, "Results for")]/div/div[./a]'):
results.append({
'link': el.xpath('./a/@href').extract_first(''),
'title': el.xpath('./a/@aria-label').extract_first('')
})
print(results)
Output from Google Maps places (shortened).
[
{
'link': 'https://www.google.com/maps/place/Black+Iron+Burger/data=!4m5!3m4!1s0x89c259acf2c7299d:0x149a07481483ce!8m2!3d40.7542649!4d-73.990364?authuser=0&hl=en&rclk=1',
'title': 'Black Iron Burger'
},
{
'link': 'https://www.google.com/maps/place/Fools+Gold+NYC/data=!4m5!3m4!1s0x89c259846e633763:0x69420cb6024065f9!8m2!3d40.723028!4d-73.989794?authuser=0&hl=en&rclk=1',
'title': 'Fools Gold NYC'
},
{
'link': 'https://www.google.com/maps/place/11th+St.+Bar/data=!4m5!3m4!1s0x89c25976492b11ff:0x14f9cacdef3eb7c1!8m2!3d40.7280546!4d-73.9812525?authuser=0&hl=en&rclk=1',
'title': '11th St. Bar'
},
...
]
Stop the Driver Once The Process of Extraction is Finished
It’s important to start and stop the driver before and after the scraping accordingly. It’s the same as you would open and close your browser before and after surfing the internet. Close the driver by running the following code.
driver.quit()
Conclusion And Recommendations on Scaling And Making The Scraper More Robust
Despite the tricky HTML structure of Google Maps, with Selenium and a good knowledge of XPath and CSS selectors, you can achieve quite good results in scraping. This method of using a browser emulator should protect you from getting blocked. However, if you are going to scale your application you might consider using proxies as well in order to avoid some unexpected troubles.
Running in Parallel
It’s possible to run drivers in multiprocessing (not multithreading) but each driver will consume one CPU. Make sure you have enough of them.
The Ultimate Way of Scraping Google Maps at Enterprise Scale
As scraping Google might be quite a challenge, many companies and big enterprises want to start scraping millions of pages without spending time on developing and maintaining their own crawlers.
The easiest way of getting started with scraping Google Maps is using Outscraper Platform (to get results in CSV files), API, or SDKs (to integrate into code).
The Easiest Way of Getting Started With Google Maps Scraping
Install Outscraper’s SDK by running the following command.
pip install google-services-api
Initialize the client and search for listings on Google or parse specific ones by sending place IDs.
* you can get API token (SECRET_API_KEY) from the profile page
from outscraper import ApiClient
api_client = ApiClient(api_key='SECRET_API_KEY')
# Search for businesses in specific locations:
result = api_client.google_maps_search('restaurants brooklyn usa', limit=20, language='en')
# Get data of the specific place by id
result = api_client.google_maps_search('ChIJrc9T9fpYwokRdvjYRHT8nI4', language='en')
# Search with many queries (batching)
result = api_client.google_maps_search([
'restaurants brooklyn usa',
'bars brooklyn usa',
], language='en')
print(result)
Result output (shortened).
[
[
{
"name": "Colonie",
"full_address": "127 Atlantic Ave, Brooklyn, NY 11201",
"borough": "Brooklyn Heights",
"street": "127 Atlantic Ave",
"city": "Brooklyn",
"postal_code": "11201",
"country_code": "US",
"country": "United States of America",
"us_state": "New York",
"state": "New York",
"plus_code": null,
"latitude": 40.6908464,
"longitude": -73.9958422,
"time_zone": "America/New_York",
"popular_times": null,
"site": "http://www.colonienyc.com/",
"phone": "+1 718-855-7500",
"type": "American restaurant",
"category": "restaurants",
"subtypes": "American restaurant, Cocktail bar, Italian restaurant, Organic restaurant, Restaurant, Wine bar",
"posts": null,
"rating": 4.6,
"reviews": 666,
"reviews_data": null,
"photos_count": 486,
"google_id": "0x89c25a4590b8c863:0xc4a4271f166de1e2",
"place_id": "ChIJY8i4kEVawokR4uFtFh8npMQ",
"reviews_link": "https://search.google.com/local/reviews?placeid=ChIJY8i4kEVawokR4uFtFh8npMQ&q=restaurants+brooklyn+usa&authuser=0&hl=en&gl=US",
"reviews_id": "-4277250731621359134",
"photo": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w800-h500-k-no",
"street_view": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w1600-h1000-k-no",
"working_hours_old_format": "Monday: 5\\u20139:30PM | Tuesday: Closed | Wednesday: Closed | Thursday: 5\\u20139:30PM | Friday: 5\\u20139:30PM | Saturday: 11AM\\u20133PM,5\\u20139:30PM | Sunday: 11AM\\u20133PM,5\\u20139:30PM",
"working_hours": {
"Monday": "5\\u20139:30PM",
"Tuesday": "Closed",
"Wednesday": "Closed",
"Thursday": "5\\u20139:30PM",
"Friday": "5\\u20139:30PM",
"Saturday": "11AM\\u20133PM,5\\u20139:30PM",
"Sunday": "11AM\\u20133PM,5\\u20139:30PM"
},
"business_status": "OPERATIONAL",
},
"reserving_table_link": "https://resy.com/cities/ny/colonie",
"booking_appointment_link": "https://resy.com/cities/ny/colonie",
"owner_id": "114275131377272904229",
"verified": true,
"owner_title": "Colonie",
"owner_link": "https://www.google.com/maps/contrib/114275131377272904229",
"location_link": "https://www.google.com/maps/place/Colonie/@40.6908464,-73.9958422,14z/data=!4m8!1m2!2m1!1sColonie!3m4!1s0x89c25a4590b8c863:0xc4a4271f166de1e2!8m2!3d40.6908464!4d-73.9958422"
...
},
...
]
]
Extra: The Easiest Way of Getting Started With Google Reviews Scraping
You can extract reviews by running the following code (assumed you have installed the python package and initiated the client).
# Get reviews of the specific place by id
result = api_client.google_maps_reviews('ChIJrc9T9fpYwokRdvjYRHT8nI4', reviewsLimit=20, language='en')
# Get reviews for places found by search query
result = api_client.google_maps_reviews('Memphis Seoul brooklyn usa', reviewsLimit=20, limit=500, language='en')
# Get only new reviews during last 24 hours
from datetime import datetime, timedelta
yesterday_timestamp = int((datetime.now() - timedelta(1)).timestamp())
result = api_client.google_maps_reviews(
'ChIJrc9T9fpYwokRdvjYRHT8nI4', sort='newest', cutoff=yesterday_timestamp, reviewsLimit=100, language='en')
Result output (shortened).
{
"name": "Memphis Seoul",
"address": "569 Lincoln Pl, Brooklyn, NY 11238, \\u0421\\u043f\\u043e\\u043b\\u0443\\u0447\\u0435\\u043d\\u0456 \\u0428\\u0442\\u0430\\u0442\\u0438",
"address_street": "569 Lincoln Pl",
"owner_id": "100347822687163365487",
"owner_link": "https://www.google.com/maps/contrib/100347822687163365487",
...
"reviews_data": [
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/112314095435657473333?hl=en-US",
"autor_name": "Eliott Levy",
"autor_id": "112314095435657473333",
"review_text": "Very good local comfort fusion food ! \\nKimchi coleslaw !! Such an amazing idea !",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s112314095435657473333!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1560692128,
"review_datetime_utc": "06/16/2019 13:35:28",
"review_likes": null
},
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/106144075337788507031?hl=en-US",
"autor_name": "fenwar1",
"autor_id": "106144075337788507031",
"review_text": "Great wings with several kinds of hot sauce. The mac and cheese ramen is excellent.\\nUPDATE:\\nReturned later to try the meatloaf slider, a thick meaty slice topped with slaw and a fantastic sauce- delicious. \\nConsider me a regular.\\ud83d\\udc4d",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s106144075337788507031!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1571100055,
"review_datetime_utc": "10/15/2019 00:40:55",
"review_likes": null
},
...
]
}
FAQ
Most frequent questions and answers
Thanks to Outscraper’s SDK, it is possible to scrape Google Maps data with Python Selenium. Check out the Outscraper Google Maps Places API documentation to see what you can do.
Using Python and Selenium, it is possible to automate the process of scraping data from Google Maps. Outscraper offers a Google Maps Places API and SDKs which simplify this task.
It is possible to automate Google Maps scraping using Python and Selenium. Outscraper Google Maps Places API and SDKs allow you to do this in the easiest way.

0 Comments