Indice
Utilizzando Selenio nello scraping dei dati è una cosa abbastanza comune. Automatizza i browser e consente di simulare le attività reali degli utenti per evitare di essere bloccati. È particolarmente utile durante lo scraping di siti JavaScript generati dinamicamente, come Google. Inoltre, aiuta a evitare qualsiasi tipo di protezione da crawling, poiché simula sostanzialmente il comportamento dei clienti reali.
In questo articolo, vedrete un tutorial passo dopo passo per sviluppare uno scraper che sarà in grado di analizzare i luoghi da Google Maps senza essere bloccato anche dopo 1000+ pagine.
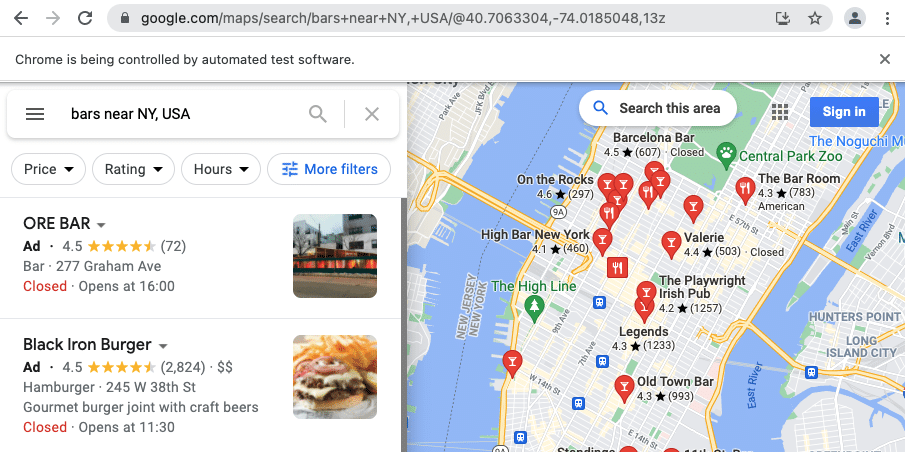
Cosa ci serve per costruire il crawler
- Python 3+.
- Browser Chrome installato.
- Selenium 3.141.0+ (pacchetto python).
- Chrome Driver (per il tuo sistema operativo).
- Parsel o qualsiasi altra libreria per estrarre dati da HTML come Beautiful Soup.
Tutorial passo dopo passo per costruire l'estrattore di Google Maps
Scaricare e salvare ChromeDriver
Per utilizzare Selenium con Google Chrome è necessario collegare il codice python al browser utilizzando ChromeDriver.
Scaricate la versione di ChromeDriver che corrisponde alla versione del vostro browser e al tipo di sistema operativo. Il numero di versione del browser Chrome può essere trovato qui: Chrom -> Icona del menu (angolo superiore destro) -> Guida -> Informazioni su Google Chrome.
Disarchivia il file chromedriver e salvalo da qualche parte sul tuo sistema (il percorso che useremo in seguito). In questo esempio di tutorial, salviamo il file nella cartella del progetto.
Installare i pacchetti Selenium e Parsel
Installate i pacchetti Selenium e Parsel eseguendo i seguenti comandi. Useremo Parsel più tardi quando analizzeremo il contenuto da HTML.
pip install selenium
pip install parsel # to extract data from HTML using XPath or CSS selectors
Inizializzare e avviare Webdriver
Prima di inizializzare Webdriver, assicurarsi di aver eseguito i passi precedenti e di avere il percorso del file chromedriver. Inizializzare il driver con il codice seguente. Si dovrebbe vedere la nuova finestra di Chrome aperta.
from selenium import webdriver
chromedrive_path = './chromedriver' # use the path to the driver you downloaded from previous steps
driver = webdriver.Chrome(chromedrive_path)
Su mac potrebbe essere visualizzato il seguente messaggio: "chromedriver non può essere aperto perché lo sviluppatore non può essere verificato". Per ovviare a questo problema, fate clic su chromedriver nel Finder, scegliete Apri dal menu e poi fate clic su Apri nella finestra di dialogo che appare. Dovreste vedere "ChromeDriver è stato avviato con successo" nella finestra del terminale aperta. Chiudetela e sarete in grado di avviare ChromeDriver dal vostro codice.
Scarica la pagina di Google Maps
Una volta avviato il driver, si è pronti ad aprire alcune pagine. Per aprire qualsiasi pagina, utilizzare il comando "get".
url = 'https://www.google.com/maps/search/bars+near+NY,+USA/@40.7443439,-74.0197995,13z'
driver.get(url)
Analizzare il contenuto della ricerca delle mappe
Una volta che la vostra pagina è aperta vedrete la pagina nella finestra del vostro browser che è controllata dal vostro codice python. Puoi eseguire il seguente codice per ottenere il contenuto della pagina HTML da ChromeDriver.
page_content = driver.page_source
Per vedere comodamente il contenuto HTML, aprite la console per sviluppatori in Chrome aprendo il menu di Chrome nell'angolo superiore destro della finestra del browser e selezionando Altri strumenti > Strumenti per sviluppatori. Ora dovreste essere in grado di vedere gli elementi della vostra pagina.
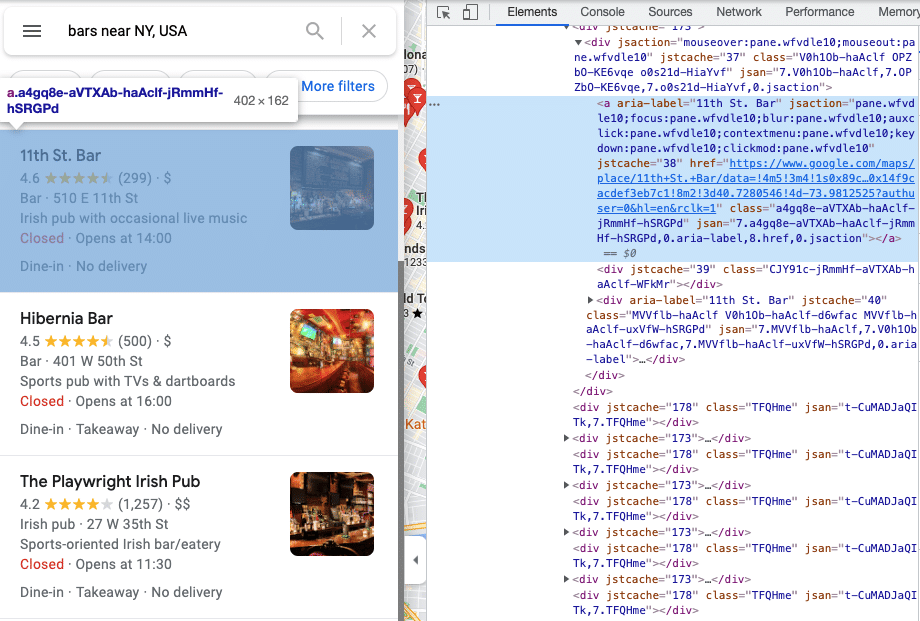
È possibile analizzare il contenuto della pagina HTML utilizzando gli strumenti di analisi preferiti. Utilizzeremo Parsel in questo tutorial.
from parsel import Selector
response = Selector(page_content)
Iterare gli elenchi e ottenere i dati di ogni luogo.
results = []
for el in response.xpath('//div[contains(@aria-label, "Results for")]/div/div[./a]'):
results.append({
'link': el.xpath('./a/@href').extract_first(''),
'title': el.xpath('./a/@aria-label').extract_first('')
})
print(results)
Output dei luoghi di Google Maps (abbreviato).
[
{
'link': 'https://www.google.com/maps/place/Black+Iron+Burger/data=!4m5!3m4!1s0x89c259acf2c7299d:0x149a07481483ce!8m2!3d40.7542649!4d-73.990364?authuser=0&hl=en&rclk=1',
'title': 'Black Iron Burger'
},
{
'link': 'https://www.google.com/maps/place/Fools+Gold+NYC/data=!4m5!3m4!1s0x89c259846e633763:0x69420cb6024065f9!8m2!3d40.723028!4d-73.989794?authuser=0&hl=en&rclk=1',
'title': 'Fools Gold NYC'
},
{
'link': 'https://www.google.com/maps/place/11th+St.+Bar/data=!4m5!3m4!1s0x89c25976492b11ff:0x14f9cacdef3eb7c1!8m2!3d40.7280546!4d-73.9812525?authuser=0&hl=en&rclk=1',
'title': '11th St. Bar'
},
...
]
Fermare il driver una volta terminato il processo di estrazione
È importante avviare e arrestare il driver prima e dopo la raschiatura. È come aprire e chiudere il browser prima e dopo la navigazione in Internet. Chiudere il driver eseguendo il seguente codice.
driver.quit()
Conclusione e raccomandazioni per scalare e rendere lo scraper più robusto
Nonostante l'insidiosa struttura HTML di Google Maps, con Selenium e una buona conoscenza di XPath e dei selettori CSS, si possono ottenere ottimi risultati nello scraping. Questo metodo di utilizzo di un emulatore di browser dovrebbe proteggervi dal rischio di essere bloccati. Tuttavia, se avete intenzione di scalare la vostra applicazione, potreste prendere in considerazione l'utilizzo di proxy per evitare problemi imprevisti.
Esecuzione in parallelo
È possibile eseguire i driver in multiprocesso (non in multithreading), ma ogni driver consumerà una CPU. Assicuratevi di averne a sufficienza.
Il modo definitivo di scraping di Google Maps su scala aziendale
Poiché lo scraping di Google potrebbe essere una bella sfida, molte aziende e grandi imprese vogliono iniziare a raschiare milioni di pagine senza spendere tempo per sviluppare e mantenere i propri crawler.
Il modo più semplice per iniziare con lo scraping di Google Maps è usare Piattaforma Outscraper (per ottenere risultati in file CSV), API, o SDKs (da integrare nel codice).
Il modo più semplice per iniziare con lo scraping di Google Maps
Installate l'SDK di Outscraper eseguendo il seguente comando.
pip install google-services-api
Inizializza il client e cerca gli annunci su Google o analizza quelli specifici inviando gli ID dei luoghi.
* si può ottenere il token API (SECRET_API_KEY) dal pagina del profilo
from outscraper import ApiClient
api_client = ApiClient(api_key='SECRET_API_KEY')
# Search for businesses in specific locations:
result = api_client.google_maps_search('restaurants brooklyn usa', limit=20, language='en')
# Get data of the specific place by id
result = api_client.google_maps_search('ChIJrc9T9fpYwokRdvjYRHT8nI4', language='en')
# Search with many queries (batching)
result = api_client.google_maps_search([
'restaurants brooklyn usa',
'bars brooklyn usa',
], language='en')
print(result)
Risultato dell'uscita (abbreviato).
[
[
{
"name": "Colonie",
"full_address": "127 Atlantic Ave, Brooklyn, NY 11201",
"borough": "Brooklyn Heights",
"street": "127 Atlantic Ave",
"city": "Brooklyn",
"postal_code": "11201",
"country_code": "US",
"country": "United States of America",
"us_state": "New York",
"state": "New York",
"plus_code": null,
"latitude": 40.6908464,
"longitude": -73.9958422,
"time_zone": "America/New_York",
"popular_times": null,
"site": "http://www.colonienyc.com/",
"phone": "+1 718-855-7500",
"type": "American restaurant",
"category": "restaurants",
"subtypes": "American restaurant, Cocktail bar, Italian restaurant, Organic restaurant, Restaurant, Wine bar",
"posts": null,
"rating": 4.6,
"reviews": 666,
"reviews_data": null,
"photos_count": 486,
"google_id": "0x89c25a4590b8c863:0xc4a4271f166de1e2",
"place_id": "ChIJY8i4kEVawokR4uFtFh8npMQ",
"reviews_link": "https://search.google.com/local/reviews?placeid=ChIJY8i4kEVawokR4uFtFh8npMQ&q=restaurants+brooklyn+usa&authuser=0&hl=en&gl=US",
"reviews_id": "-4277250731621359134",
"photo": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w800-h500-k-no",
"street_view": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w1600-h1000-k-no",
"working_hours_old_format": "Monday: 5\\u20139:30PM | Tuesday: Closed | Wednesday: Closed | Thursday: 5\\u20139:30PM | Friday: 5\\u20139:30PM | Saturday: 11AM\\u20133PM,5\\u20139:30PM | Sunday: 11AM\\u20133PM,5\\u20139:30PM",
"working_hours": {
"Monday": "5\\u20139:30PM",
"Tuesday": "Closed",
"Wednesday": "Closed",
"Thursday": "5\\u20139:30PM",
"Friday": "5\\u20139:30PM",
"Saturday": "11AM\\u20133PM,5\\u20139:30PM",
"Sunday": "11AM\\u20133PM,5\\u20139:30PM"
},
"business_status": "OPERATIONAL",
},
"reserving_table_link": "https://resy.com/cities/ny/colonie",
"booking_appointment_link": "https://resy.com/cities/ny/colonie",
"owner_id": "114275131377272904229",
"verified": true,
"owner_title": "Colonie",
"owner_link": "https://www.google.com/maps/contrib/114275131377272904229",
"location_link": "https://www.google.com/maps/place/Colonie/@40.6908464,-73.9958422,14z/data=!4m8!1m2!2m1!1sColonie!3m4!1s0x89c25a4590b8c863:0xc4a4271f166de1e2!8m2!3d40.6908464!4d-73.9958422"
...
},
...
]
]
Extra: Il modo più semplice per iniziare con lo scraping delle recensioni di Google
Puoi estrarre le recensioni eseguendo il seguente codice (supponendo che tu abbia installato il pacchetto python e avviato il client).
# Get reviews of the specific place by id
result = api_client.google_maps_reviews('ChIJrc9T9fpYwokRdvjYRHT8nI4', reviewsLimit=20, language='en')
# Get reviews for places found by search query
result = api_client.google_maps_reviews('Memphis Seoul brooklyn usa', reviewsLimit=20, limit=500, language='en')
# Get only new reviews during last 24 hours
from datetime import datetime, timedelta
yesterday_timestamp = int((datetime.now() - timedelta(1)).timestamp())
result = api_client.google_maps_reviews(
'ChIJrc9T9fpYwokRdvjYRHT8nI4', sort='newest', cutoff=yesterday_timestamp, reviewsLimit=100, language='en')
Risultato dell'uscita (abbreviato).
{
"name": "Memphis Seoul",
"address": "569 Lincoln Pl, Brooklyn, NY 11238, \\u0421\\u043f\\u043e\\u043b\\u0443\\u0447\\u0435\\u043d\\u0456 \\u0428\\u0442\\u0430\\u0442\\u0438",
"address_street": "569 Lincoln Pl",
"owner_id": "100347822687163365487",
"owner_link": "https://www.google.com/maps/contrib/100347822687163365487",
...
"reviews_data": [
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/112314095435657473333?hl=en-US",
"autor_name": "Eliott Levy",
"autor_id": "112314095435657473333",
"review_text": "Very good local comfort fusion food ! \\nKimchi coleslaw !! Such an amazing idea !",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s112314095435657473333!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1560692128,
"review_datetime_utc": "06/16/2019 13:35:28",
"review_likes": null
},
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/106144075337788507031?hl=en-US",
"autor_name": "fenwar1",
"autor_id": "106144075337788507031",
"review_text": "Great wings with several kinds of hot sauce. The mac and cheese ramen is excellent.\\nUPDATE:\\nReturned later to try the meatloaf slider, a thick meaty slice topped with slaw and a fantastic sauce- delicious. \\nConsider me a regular.\\ud83d\\udc4d",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s106144075337788507031!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1571100055,
"review_datetime_utc": "10/15/2019 00:40:55",
"review_likes": null
},
...
]
}
Domande frequenti
Domande e risposte più frequenti
Grazie all'SDK di Outscraper, è possibile effettuare lo scrape dei dati di Google Maps con Python Selenium. Consultate la documentazione dell'API di Google Maps Places di Outscraper per vedere cosa potete fare.
Utilizzando Python e Selenium, è possibile automatizzare il processo di scraping dei dati da Google Maps. Outscraper offre un API Places di Google Maps e SDK che semplificano questo compito.
È possibile automatizzare lo scraping di Google Maps utilizzando Python e Selenium. Outscraper Google Maps Places API e gli SDK consentono di farlo nel modo più semplice.
0 Comments