Das Inhaltsverzeichnis
Verwendung von Selen in Data Scraping ist eine weit verbreitete Sache. Es automatisiert die Browser und ermöglicht es Ihnen, echte Benutzeraktivitäten zu simulieren, um eine Blockierung zu vermeiden. Es ist besonders hilfreich beim Scraping von dynamisch generierten JavaScript-Seiten wie Google. Außerdem hilft es, jegliche Art von Crawling-Schutz zu vermeiden, da es im Grunde das Verhalten echter Kunden simuliert.
In diesem Artikel sehen Sie eine Schritt-für-Schritt-Anleitung zur Entwicklung eines Scrapers, der in der Lage ist, Orte aus Google Maps zu analysieren, ohne selbst nach über 1000 Seiten blockiert zu werden.
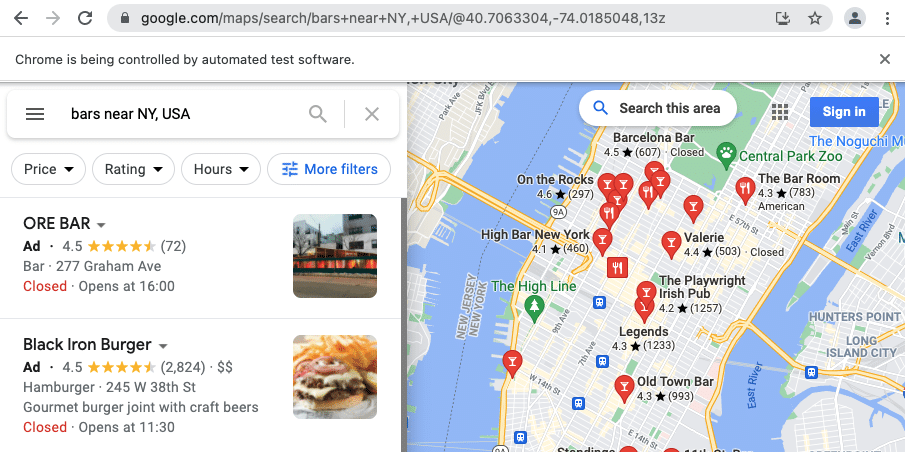
Was wir für den Bau des Crawlers benötigen
- Python 3+.
- Chrome-Browser installiert.
- Selenium 3.141.0+ (Python-Paket).
- Chrome-Treiber (für Ihr Betriebssystem).
- Parsel oder eine andere Bibliothek zur Extraktion von Daten aus HTML wie Beautiful Soup.
Schritt-für-Schritt-Anleitung zum Erstellen des Google Maps Extractors
ChromeDriver herunterladen und speichern
Um Selenium mit Google Chrome zu verwenden, müssen Sie Python-Code mit dem Browser verknüpfen, indem Sie ChromeDriver.
Laden Sie die Version von ChromeDriver herunter, die Ihrer Browserversion und Ihrem Betriebssystemtyp entspricht. Die Versionsnummer Ihres Chrome-Browsers können Sie hier finden: Chrom -> Menüsymbol (obere rechte Ecke) -> Hilfe -> Über Google Chrome.
Entpacken Sie die Chromedriver-Datei und speichern Sie sie irgendwo auf Ihrem System (den Pfad dazu werden wir später verwenden). In diesem Übungsbeispiel speichern wir die Datei im Projektordner.
Selenium- und Parsel-Pakete installieren
Installieren Sie die Pakete Selenium und Parsel, indem Sie die folgenden Befehle ausführen. Wir werden Parsel später verwenden, wenn wir Inhalte aus HTML parsen.
pip install selenium
pip install parsel # to extract data from HTML using XPath or CSS selectors
Webdriver initialisieren und starten
Bevor Sie den Webdriver initialisieren, vergewissern Sie sich, dass Sie die vorherigen Schritte durchgeführt haben und dass Sie den Pfad zu Ihrer Chromedriver-Datei haben. Initialisieren Sie den Treiber mit dem folgenden Code. Sie sollten sehen, dass sich das neue Chrome-Fenster öffnet.
from selenium import webdriver
chromedrive_path = './chromedriver' # use the path to the driver you downloaded from previous steps
driver = webdriver.Chrome(chromedrive_path)
Auf dem Mac sehen Sie möglicherweise Folgendes: "chromedriver kann nicht geöffnet werden, weil der Entwickler nicht verifiziert werden kann". Um dieses Problem zu beheben, klicken Sie bei gedrückter Maustaste auf den Chromedriver im Finder, wählen Sie im Menü den Eintrag Öffnen und klicken Sie dann im erscheinenden Dialog auf Öffnen. Im geöffneten Terminalfenster sollten Sie "ChromeDriver wurde erfolgreich gestartet" sehen. Schließen Sie es und danach können Sie ChromeDriver aus Ihrem Code heraus starten.
Google Maps Seite herunterladen
Once you start the driver you are ready to open some pages. To open any page, use the “get” command.
url = 'https://www.google.com/maps/search/bars+near+NY,+USA/@40.7443439,-74.0197995,13z'
driver.get(url)
Parsen von Karten Suchinhalt
Sobald Ihre Seite geöffnet ist, sehen Sie die Seite in Ihrem Browserfenster, die von Ihrem Python-Code gesteuert wird. Sie können den folgenden Code ausführen, um den HTML-Seiteninhalt von ChromeDriver abzurufen.
page_content = driver.page_source
Um den HTML-Inhalt bequem zu sehen, öffnen Sie die Entwicklerkonsole in Chrome, indem Sie das Chrome-Menü in der oberen rechten Ecke des Browserfensters öffnen und Mehr Tools > Entwicklertools wählen. Jetzt sollten Sie die Elemente Ihrer Seite sehen können.
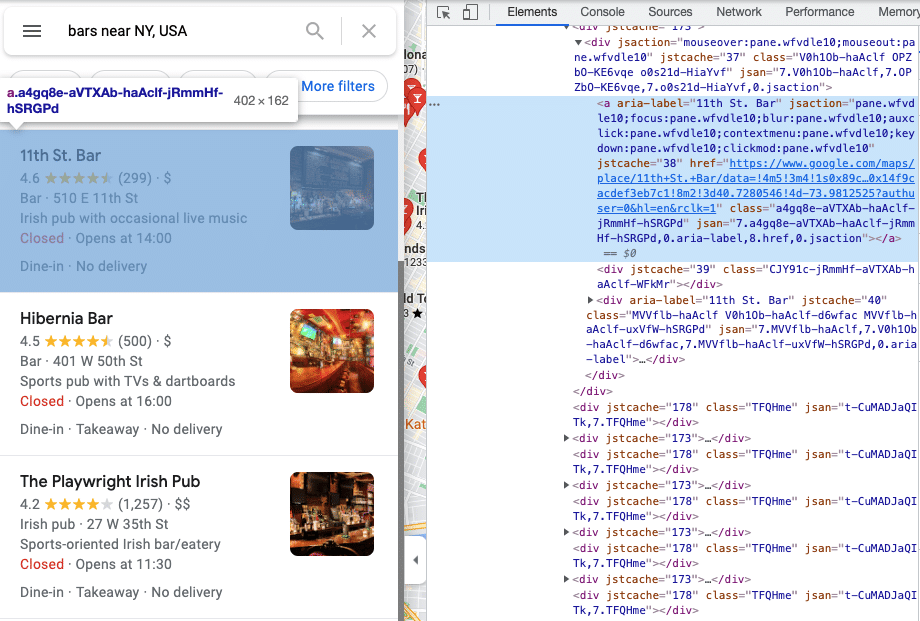
Sie können den Inhalt der HTML-Seite mit Hilfe Ihrer bevorzugten Parsing-Tools analysieren. Wir verwenden Parsel in diesem Lernprogramm.
from parsel import Selector
response = Selector(page_content)
Iterate over listings and get each place’s data.
results = []
for el in response.xpath('//div[contains(@aria-label, "Results for")]/div/div[./a]'):
results.append({
'link': el.xpath('./a/@href').extract_first(''),
'title': el.xpath('./a/@aria-label').extract_first('')
})
print(results)
Output from Google Maps places (shortened).
[
{
'link': 'https://www.google.com/maps/place/Black+Iron+Burger/data=!4m5!3m4!1s0x89c259acf2c7299d:0x149a07481483ce!8m2!3d40.7542649!4d-73.990364?authuser=0&hl=en&rclk=1',
'title': 'Black Iron Burger'
},
{
'link': 'https://www.google.com/maps/place/Fools+Gold+NYC/data=!4m5!3m4!1s0x89c259846e633763:0x69420cb6024065f9!8m2!3d40.723028!4d-73.989794?authuser=0&hl=en&rclk=1',
'title': 'Fools Gold NYC'
},
{
'link': 'https://www.google.com/maps/place/11th+St.+Bar/data=!4m5!3m4!1s0x89c25976492b11ff:0x14f9cacdef3eb7c1!8m2!3d40.7280546!4d-73.9812525?authuser=0&hl=en&rclk=1',
'title': '11th St. Bar'
},
...
]
Stoppen Sie den Treiber, sobald der Extraktionsprozess abgeschlossen ist
Es ist wichtig, den Treiber vor und nach dem Scrapen entsprechend zu starten und zu stoppen. Das ist dasselbe, wie wenn Sie Ihren Browser vor und nach dem Surfen im Internet öffnen und schließen würden. Schließen Sie den Treiber, indem Sie den folgenden Code ausführen.
driver.quit()
Schlussfolgerung und Empfehlungen zur Skalierung und zur Verbesserung der Robustheit des Scrapers
Trotz der komplizierten HTML-Struktur von Google Maps können Sie mit Selenium und guten Kenntnissen von XPath und CSS-Selektoren recht gute Ergebnisse beim Scraping erzielen. Diese Methode der Verwendung eines Browser-Emulators sollte Sie davor schützen, blockiert zu werden. Wenn Sie Ihre Anwendung jedoch skalieren wollen, sollten Sie auch die Verwendung von Proxys in Betracht ziehen, um unerwartete Probleme zu vermeiden.
Parallel laufen
Es ist möglich, Treiber im Multiprocessing (nicht Multithreading) zu betreiben, aber jeder Treiber verbraucht eine CPU. Stellen Sie sicher, dass Sie genug davon haben.
Der ultimative Weg zum Scraping von Google Maps im Unternehmensmaßstab
Da das Scrapen von Google eine ziemliche Herausforderung sein kann, möchten viele Firmen und große Unternehmen mit dem Scrapen von Millionen von Seiten beginnen, ohne Zeit in die Entwicklung und Wartung ihrer eigenen Crawler zu investieren.
Der einfachste Weg, um mit dem Scrapen von Google Maps zu beginnen, ist die Verwendung von Outscraper-Plattform (um Ergebnisse in CSV-Dateien zu erhalten), API, oder SDKs (zur Integration in den Code).
Der einfachste Weg, um mit Google Maps Scraping anzufangen
Install Outscraper’s SDK by running the following command.
pip install google-services-api
Initialisieren Sie den Client und suchen Sie nach Einträgen in Google oder analysieren Sie bestimmte Einträge durch Senden von Orts-IDs.
* Sie können das API-Token (SECRET_API_KEY) aus dem Profilseite
from outscraper import ApiClient
api_client = ApiClient(api_key='SECRET_API_KEY')
# Search for businesses in specific locations:
result = api_client.google_maps_search('restaurants brooklyn usa', limit=20, language='en')
# Get data of the specific place by id
result = api_client.google_maps_search('ChIJrc9T9fpYwokRdvjYRHT8nI4', language='en')
# Search with many queries (batching)
result = api_client.google_maps_search([
'restaurants brooklyn usa',
'bars brooklyn usa',
], language='en')
print(result)
Ergebnisausgabe (gekürzt).
[
[
{
"name": "Colonie",
"full_address": "127 Atlantic Ave, Brooklyn, NY 11201",
"borough": "Brooklyn Heights",
"street": "127 Atlantic Ave",
"city": "Brooklyn",
"postal_code": "11201",
"country_code": "US",
"country": "United States of America",
"us_state": "New York",
"state": "New York",
"plus_code": null,
"latitude": 40.6908464,
"longitude": -73.9958422,
"time_zone": "America/New_York",
"popular_times": null,
"site": "http://www.colonienyc.com/",
"phone": "+1 718-855-7500",
"type": "American restaurant",
"category": "restaurants",
"subtypes": "American restaurant, Cocktail bar, Italian restaurant, Organic restaurant, Restaurant, Wine bar",
"posts": null,
"rating": 4.6,
"reviews": 666,
"reviews_data": null,
"photos_count": 486,
"google_id": "0x89c25a4590b8c863:0xc4a4271f166de1e2",
"place_id": "ChIJY8i4kEVawokR4uFtFh8npMQ",
"reviews_link": "https://search.google.com/local/reviews?placeid=ChIJY8i4kEVawokR4uFtFh8npMQ&q=restaurants+brooklyn+usa&authuser=0&hl=en&gl=US",
"reviews_id": "-4277250731621359134",
"photo": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w800-h500-k-no",
"street_view": "https://lh5.googleusercontent.com/p/AF1QipN_Ani32z-7b9XD182oeXKgQ-DIhLcgL09gyMZf=w1600-h1000-k-no",
"working_hours_old_format": "Monday: 5\\u20139:30PM | Tuesday: Closed | Wednesday: Closed | Thursday: 5\\u20139:30PM | Friday: 5\\u20139:30PM | Saturday: 11AM\\u20133PM,5\\u20139:30PM | Sunday: 11AM\\u20133PM,5\\u20139:30PM",
"working_hours": {
"Monday": "5\\u20139:30PM",
"Tuesday": "Closed",
"Wednesday": "Closed",
"Thursday": "5\\u20139:30PM",
"Friday": "5\\u20139:30PM",
"Saturday": "11AM\\u20133PM,5\\u20139:30PM",
"Sunday": "11AM\\u20133PM,5\\u20139:30PM"
},
"business_status": "OPERATIONAL",
},
"reserving_table_link": "https://resy.com/cities/ny/colonie",
"booking_appointment_link": "https://resy.com/cities/ny/colonie",
"owner_id": "114275131377272904229",
"verified": true,
"owner_title": "Colonie",
"owner_link": "https://www.google.com/maps/contrib/114275131377272904229",
"location_link": "https://www.google.com/maps/place/Colonie/@40.6908464,-73.9958422,14z/data=!4m8!1m2!2m1!1sColonie!3m4!1s0x89c25a4590b8c863:0xc4a4271f166de1e2!8m2!3d40.6908464!4d-73.9958422"
...
},
...
]
]
Extra: Der einfachste Weg, mit dem Scraping von Google-Bewertungen anzufangen
Sie können Bewertungen extrahieren, indem Sie den folgenden Code ausführen (vorausgesetzt, Sie haben das Python-Paket installiert und den Client gestartet).
# Get reviews of the specific place by id
result = api_client.google_maps_reviews('ChIJrc9T9fpYwokRdvjYRHT8nI4', reviewsLimit=20, language='en')
# Get reviews for places found by search query
result = api_client.google_maps_reviews('Memphis Seoul brooklyn usa', reviewsLimit=20, limit=500, language='en')
# Get only new reviews during last 24 hours
from datetime import datetime, timedelta
yesterday_timestamp = int((datetime.now() - timedelta(1)).timestamp())
result = api_client.google_maps_reviews(
'ChIJrc9T9fpYwokRdvjYRHT8nI4', sort='newest', cutoff=yesterday_timestamp, reviewsLimit=100, language='en')
Ergebnisausgabe (gekürzt).
{
"name": "Memphis Seoul",
"address": "569 Lincoln Pl, Brooklyn, NY 11238, \\u0421\\u043f\\u043e\\u043b\\u0443\\u0447\\u0435\\u043d\\u0456 \\u0428\\u0442\\u0430\\u0442\\u0438",
"address_street": "569 Lincoln Pl",
"owner_id": "100347822687163365487",
"owner_link": "https://www.google.com/maps/contrib/100347822687163365487",
...
"reviews_data": [
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/112314095435657473333?hl=en-US",
"autor_name": "Eliott Levy",
"autor_id": "112314095435657473333",
"review_text": "Very good local comfort fusion food ! \\nKimchi coleslaw !! Such an amazing idea !",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s112314095435657473333!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1560692128,
"review_datetime_utc": "06/16/2019 13:35:28",
"review_likes": null
},
{
"google_id": "0x89c25bb5950fc305:0x330a88bf1482581d",
"autor_link": "https://www.google.com/maps/contrib/106144075337788507031?hl=en-US",
"autor_name": "fenwar1",
"autor_id": "106144075337788507031",
"review_text": "Great wings with several kinds of hot sauce. The mac and cheese ramen is excellent.\\nUPDATE:\\nReturned later to try the meatloaf slider, a thick meaty slice topped with slaw and a fantastic sauce- delicious. \\nConsider me a regular.\\ud83d\\udc4d",
"review_link": "https://www.google.com/maps/reviews/data=!4m5!14m4!1m3!1m2!1s106144075337788507031!2s0x0:0x330a88bf1482581d?hl=en-US",
"review_rating": 5,
"review_timestamp": 1571100055,
"review_datetime_utc": "10/15/2019 00:40:55",
"review_likes": null
},
...
]
}
FAQ
Häufigste Fragen und Antworten
Thanks to Outscraper’s SDK, it is possible to scrape Google Maps data with Python Selenium. Check out the Outscraper Google Maps Places API documentation to see what you can do.
Using Python and Selenium, it is possible to automate the process of scraping data from Google Maps. Outscraper offers a Google Maps Orte API and SDKs which simplify this task.
It is possible to automate Google Maps scraping using Python and Selenium. Outscraper Google Maps Orte API and SDKs allow you to do this in the easiest way.
0 Kommentare